



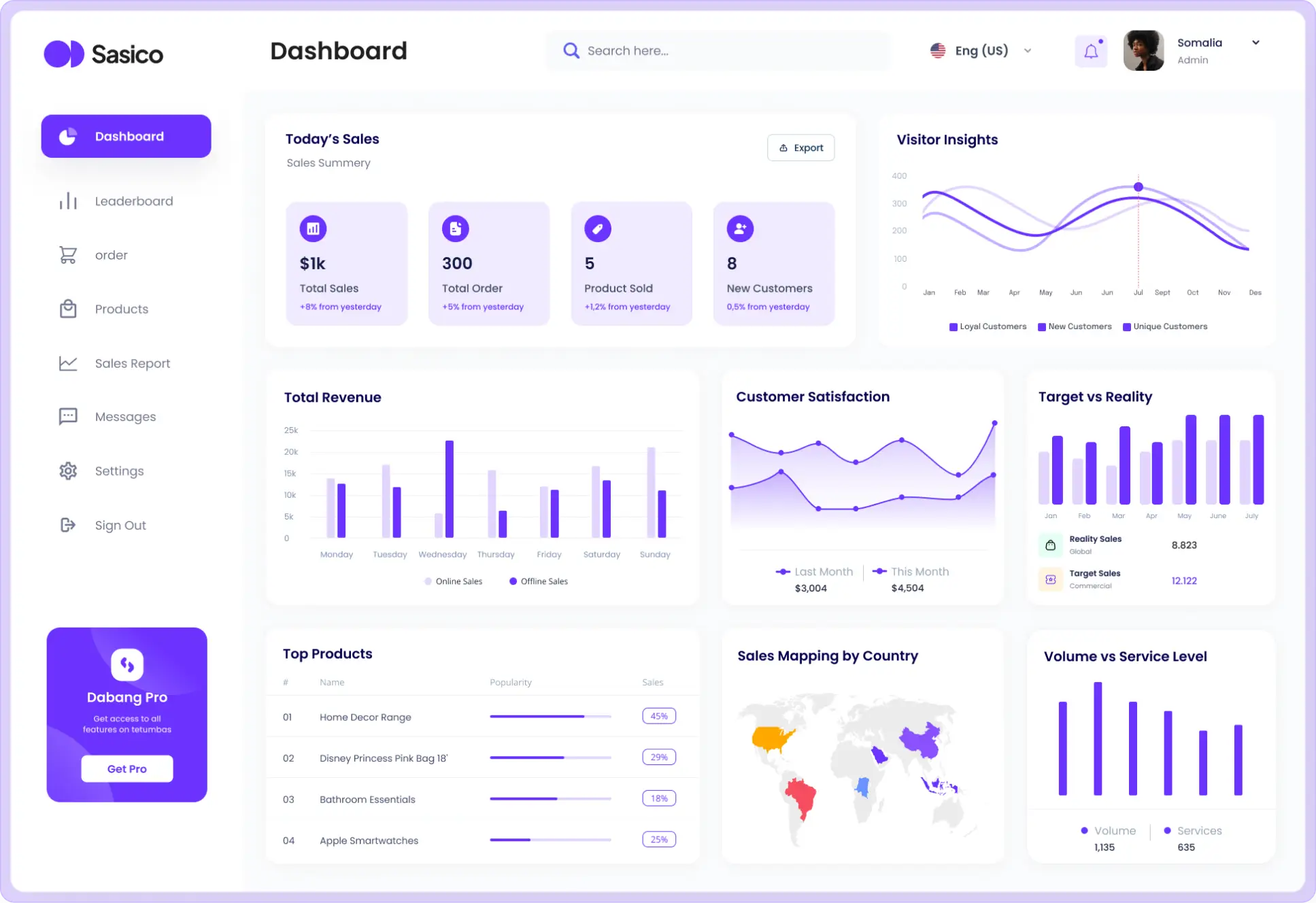
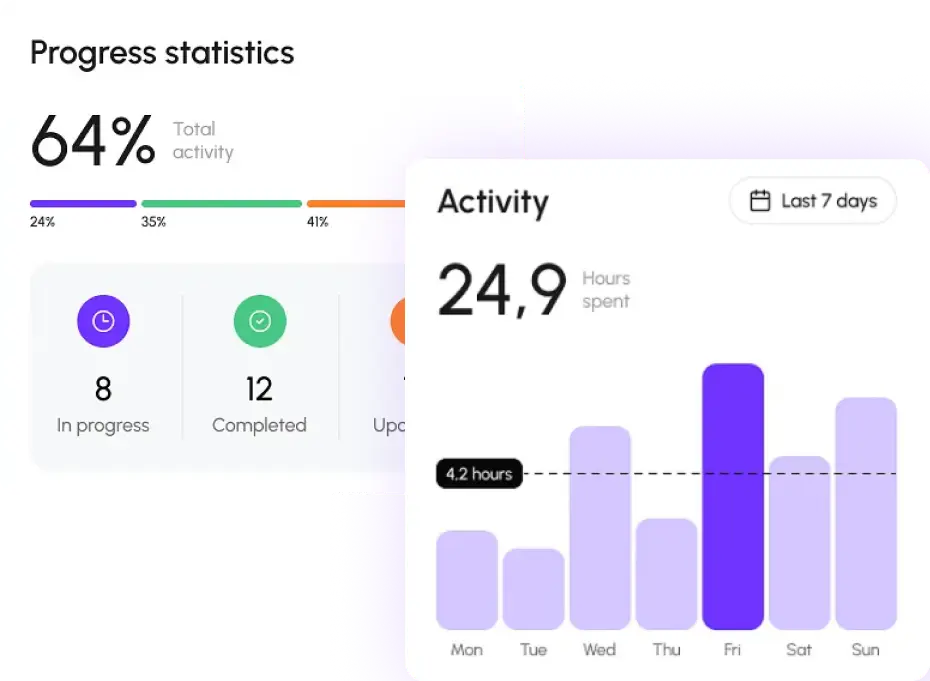
(01) Legacy + Future Metadata, Unified


(02) True Single Source of Truth


(03) No Vendor Lock-In, Ever
(04) Maximize Efficiency, Minimize Cost
(05) Mix, Match, and Continuously Improve


(01)
Legacy + Future Metadata, Unified
(02) True Single Source of Truth
(03) No Vendor Lock-In, Ever
(04) Maximize Efficiency, Minimize Cost
(05) Mix, Match, and Continuously Improve
(02)
True Single Source of Truth
(03) No Vendor Lock-In, Ever
(04) Maximize Efficiency, Minimize Cost
(05) Mix, Match, and Continuously Improve
(03)
No Vendor Lock-In, Ever
(04) Maximize Efficiency, Minimize Cost
(05) Mix, Match, and Continuously Improve
(04)
Maximize Efficiency, Minimize Cost
(05) Mix, Match, and Continuously Improve
(05)
Mix, Match, and Continuously Improve